สำหรับส่วนนี้ จะเป็นส่วนที่ผมได้ลองหยิบ dataset จาก Kaggle มาลองใช้ทักษะทั้งหมดที่ได้เรียนมาเพื่อ ตอบคำถามจาก User ในที่นี้ User คือ Gemini
ผมได้ทำการจ้างผู้เชี่ยวชาญโดยการให้สร้างให้ Gemini เป็นจำลองเป็น Manager ขององค์กรแห่งหนึ่งและทำการวิเคราะห์และตั้งโจทย์คำถามจาก dataset ที่เลือกมา แล้วผมจะเป็นผู้ตอบคำถามเหล่านั้น
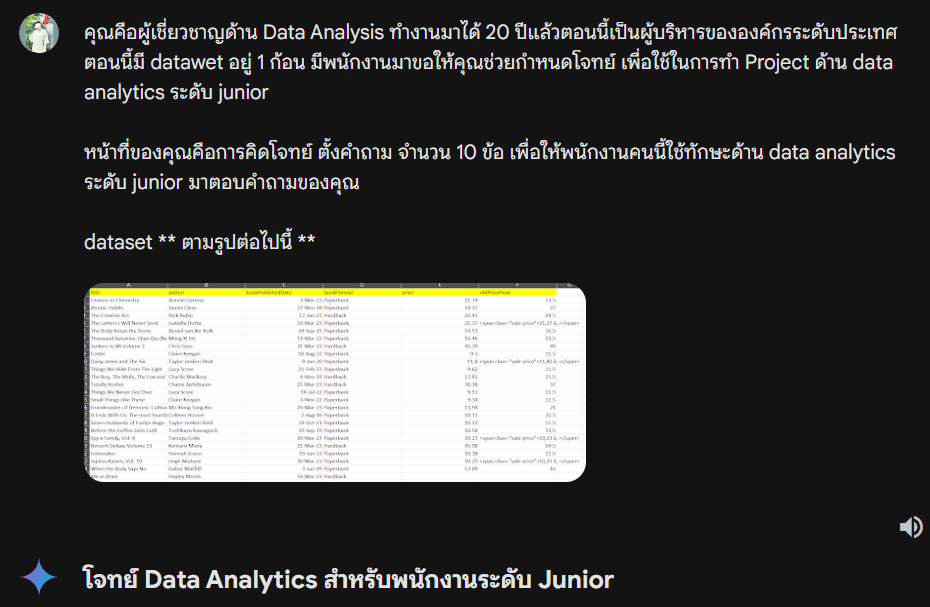
ซึ่งก่อนจะไปดู Project เหล่านั้นกัน เดี๋ยวผมจะขอลองยกตัวอย่าง Project สัก 1 ชิ้นที่ได้ใช้ทักษะของ Python และ library pandas และ numpy ที่ศึกษาจาก DataRockie Bootcamp มาให้ดูเป็นตัวอย่าง เพื่อให้ทุกท่านได้เห็นแนวคิด และเทคนิคพื้นฐานที่ผมนำมาใช้ในการวิเคราะห์ข้อมูล และทำ Project ต่างๆกันดูนะครับ
PROJECT#0 THIS IS MY FIRST PROJECT FROM Datarockie “Sample store”
เริ่มต้นจากที่เรามี Dataset อยู่ 1 ไฟล์ เป็นไฟล์ .CSV เราจะใช้ทักษะของ python มาวิเคราะห์ข้อมูล แล้วตอบคำถามทั้งหมด 10+1 คำถามต่อไปนี้
TODO 01 – how many columns, rows in this dataset
TODO 02 – is there any missing values?, if there is, which colunm? how many nan values?
TODO 03 – your friend ask for California data, filter it and export csv for him
TODO 04 – your friend ask for all order data in California and Texas in 2017 (look at Order Date), send him csv file
TODO 05 – how much total sales, average sales, and standard deviation of sales your company make in 2017
TODO 06 – which Segment has the highest profit in 2018
TODO 07 – which top 5 States have the least total sales between 15 April 2019 – 31 December 2019
TODO 08 – what is the proportion of total sales (%) in West + Central in 2019 e.g. 25%
TODO 09 – find top 10 popular products in terms of number of orders vs. total sales during 2019-2020
TODO 10 – plot at least 2 plots, any plot you think interesting 🙂
เราเริ่มจากการเพิ่ม library pandas และ numpy เข้าไปก่อน ** พยายามทำให้เป็นนิสัย **

จากนั้นจะทำการอ่านไฟล์ .CSV โดยการใช้ library pandas เข้ามาช่วย
(pd.read_csv(*)) ภายในเครื่องหมาย * เป็นชื่อไฟล์

ขั้นตอนถัดไป ก่อนที่จะทำการวิเคราะห์ข้อมูล เราจะทำการ Check data ก่อนทุกครั้ง โดยการใช้คำสั่งต่อไปนี้ ** พยายามทำให้เป็นนิสัย **
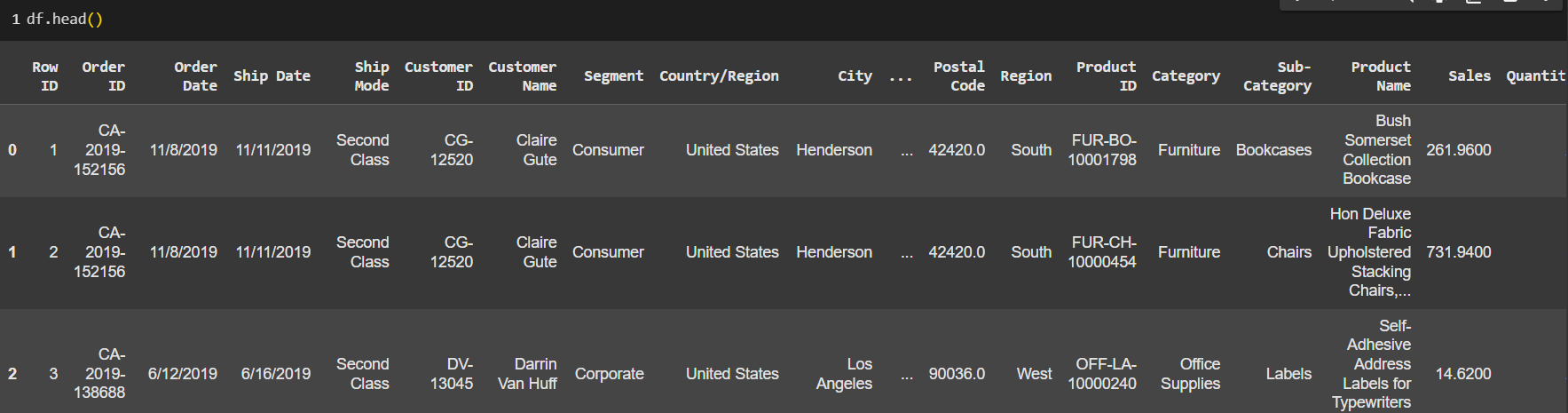
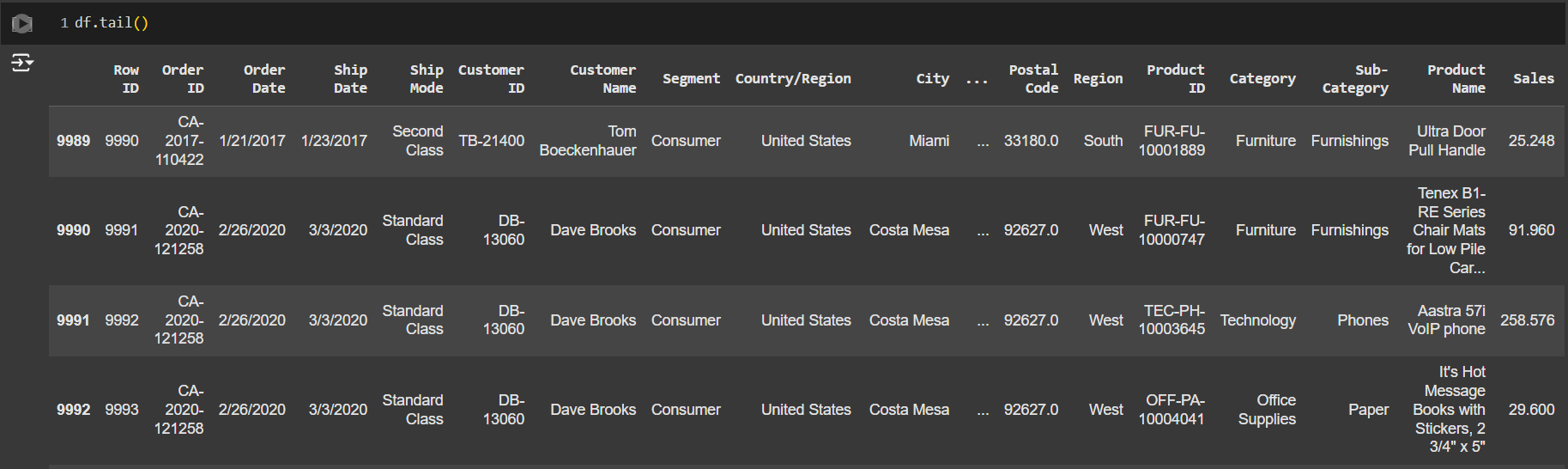
df.head() , df.tail()
เพื่อเช็คข้อมูล 5 แถวบนสุด และ 5 แถวล่างสุดของ dataset
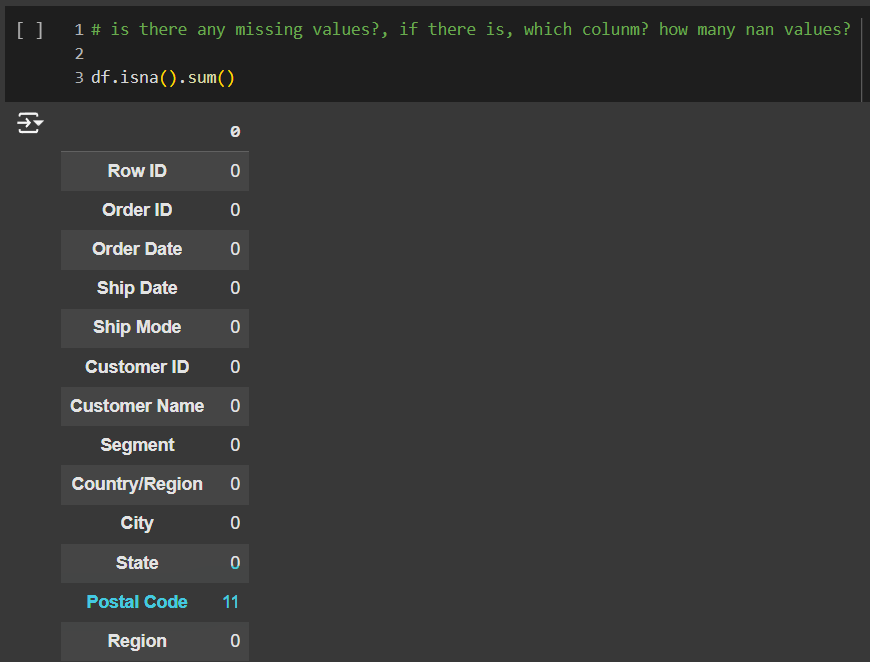
df.shape , df.info()
เพื่อ check จำนวน column & rows และ missing values และมีการตอบคำถามข้อที่ 1 ด้วย
TODO 01 – how many columns, rows in this dataset
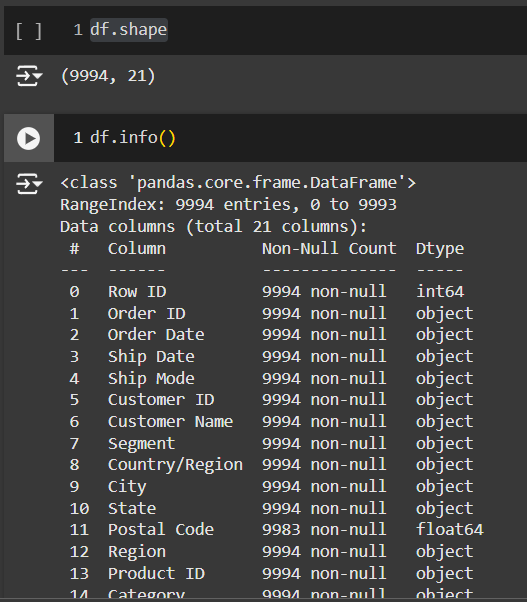
จะเห็นได้ว่า column Postal Code จะมี missing values อยู่ 11 cell เราจะลองตรวจสอบว่าถูกต้องหรือไม่ โดยการใช้คำสัั่ง
df[‘Postal Code’].isnull().sum()
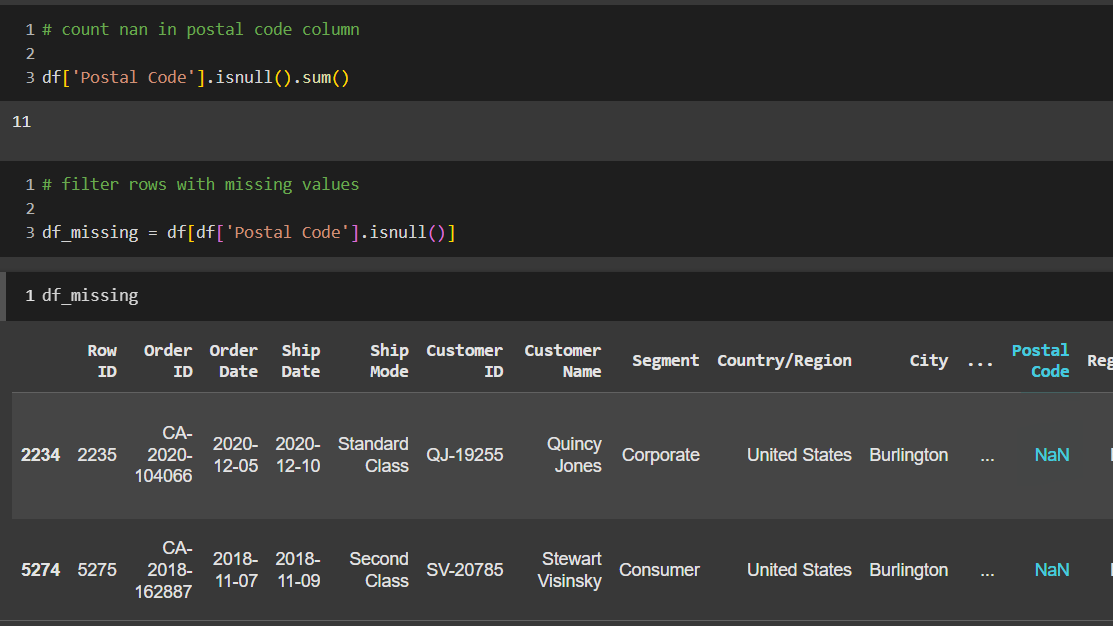
จากนั้น จะทำการดึงข้อมูล data จากไฟล์ต้นฉบับ ที่เอาเฉพาะ rows ที่มีค่า Postal Code เป็นค่าว่างออกมาสร้างเป็น dataframe ก้อนใหม่โดยเขียนเพิ่มเติมดังนี้
df_missing = df[df[‘Postal Code’].isnull()]
เท่านี้เราก็ได้ dataframe ก้อนใหม่ที่มี Postal Code เป็นค่าว่างออกมาเรียบร้อย
TODO 02 – is there any missing values?, if there is, which column? how many nan values?
TODO 03 – your friend ask for California data, filter it and export csv for him
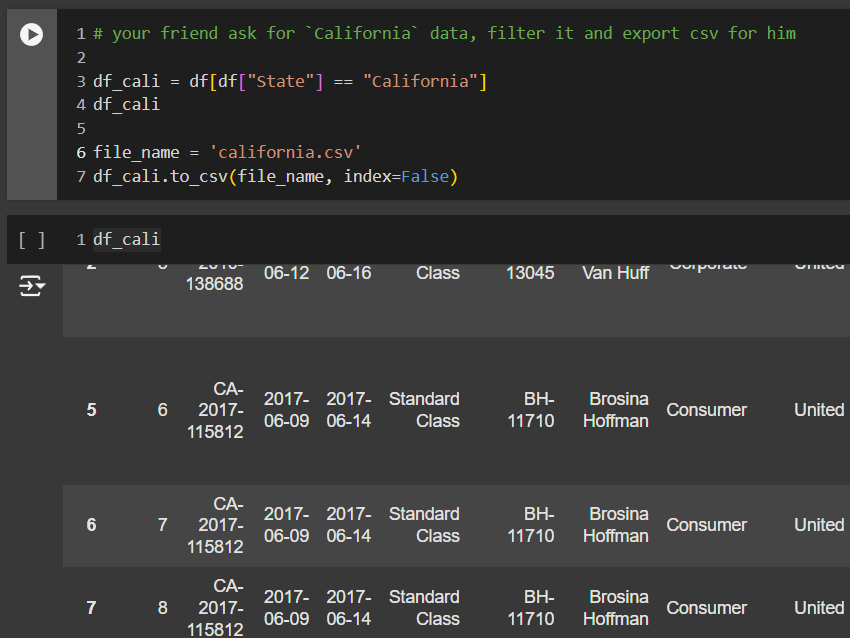
คำถามข้อที่ 3 นี้ เป็นการ Filter โดย User อยากได้ข้อมูลเฉพาะ State ที่เป็น California เท่านั้น เราจึงต้อง Filter โดยใช้คำสั่งดังนี้
df_cali = df[df[“State”] == “California”]
เป็นการ Filter column “State” โดยเอาเฉพาะที่มีคำว่า “California” เท่านั้น และให้แสดงข้อมูลออกมาทั้งแถว และแทนค่าผลลัพธ์ในให้อยู่ใน dataframe ที่ชื่อว่า df_cali
เมื่อได้ข้อมูลแล้วเราจะส่งไฟล์นี้กลับให้เพื่อเรา ซึ่งต้องการไฟล์ .CSV เราจะต้องเขียนคำสั่งดังนี้
file_name = ‘california.csv’
df_cali.to_csv(file_name, index=False)
คำสั่งนี่เริ่มต้นจากกำหนดชื่อไฟล์ที่เราจะ export ออกมา ในที่นี้ไฟล์จะชื่อว่า california.csv
จากนั้นใช้คำสั่งจากในการ create ไฟล์
df_cali.to_csv(‘california.csv’, index=False)
'california.csv': จะเป็นชื่อไฟล์ที่ต้องการสร้าง ส่วน index=False: เราจพใส่เพื่อป้องกันไม่ให้ index ของ Dataframe ถูก save ลงในไฟล์
TODO 04 – your friend ask for all order data in California and Texas in 2017 (look at Order Date), send him csv file
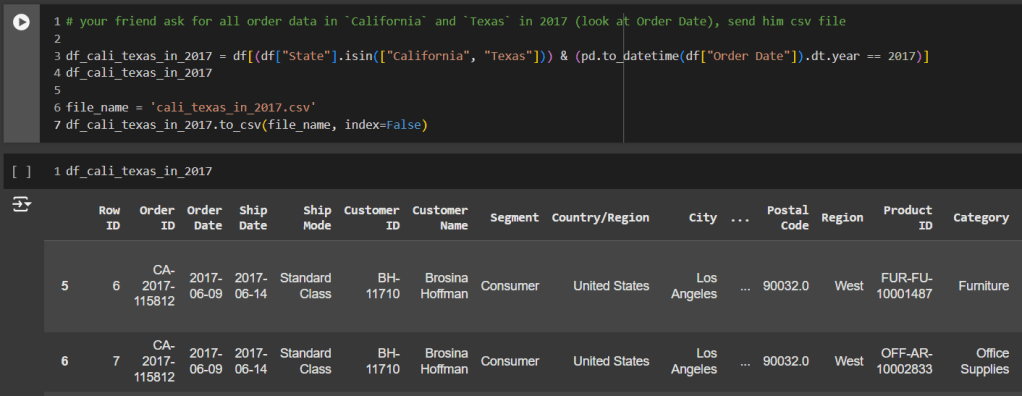
คำถามข้อที่ 4 นี้ เราต้องการหาผลลัพธ์ของ State ที่เป็น California และ Texas ในปี 2017 อิงจาก Column Order date เท่านั้น
เริ่มจากการสร้างคำสั่ง Filter ตามโจทย์ความต้องการของ User ก่อน
ผมเริ่มจากวันที่ก่อน เพราะต้องการเปลี่ยนรูปแบบวันที่ให้เป็น datetime เพื่อให้สามารถทำการเปรียบเทียบวันที่ได้ เพราะจากที่เราตรวจสอบในตอนต้นก่อนเริ่มทำการตอบคำถาม จะเห็นได้ว่า column Order date เป็น type Object ผมจึงใช้คำสั่งต่อไปนี้
pd.to_datetime(df["Order Date"])
จากนั้นเราเอาเฉพาะค่าที่เป็นปี 2017 โดยเพิ่มคำสั่งต่อท้ายดังนี้
pd.to_datetime(df[“Order Date”]).dt.year == 2017
คำสั่ง .dt.year หมายความว่า เอารูปแบบ Year ที่มีค่าเท่ากับ 2017 เท่านั้น
หลังจากนั้นก็ filter อีกส่วนหนึ่งคือ State ที่เป็น California และ Texas
(df[“State”].isin([“California”, “Texas”]))
จากนั้นก็นำทั้ง 2 ส่วนมารวมกัน โดยการ Filter มากกว่า 1 เงื่อนไข เราจะใส่เครื่องหมาย & เข้าไป เราสร้าง dataframe ใหม่ขึ้มาชื่อว่า df_cali_texas_in_2017
df_cali_texas_in_2017 = df[(df[“State”].isin([“California”, “Texas”])) & (pd.to_datetime(df[“Order Date”]).dt.year == 2017)]
พอเสร็จเรียบร้อยเราก็ Export ข้อมูลส่งให้เพื่อนเราใหม่อีกครั้ง
TODO 05 – how much total sales, average sales, and standard deviation of sales your company make in 2017
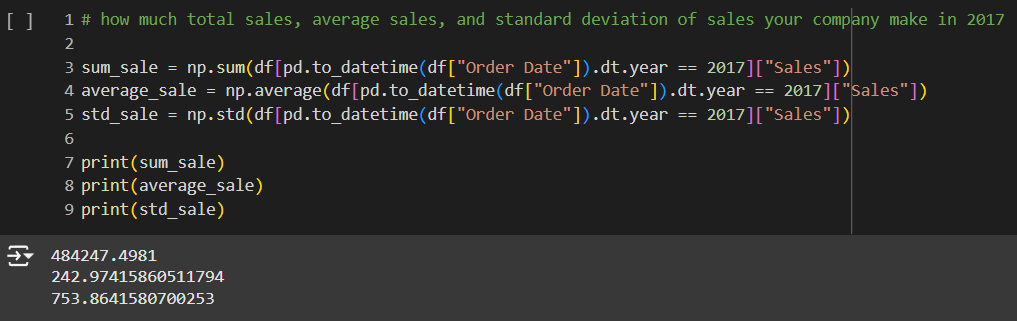
คำถามถัดมาเราต้องการหาค่าของยอดขายในปี 2017 เพราะฉะนั้นก่อนอื่นเราใช้เทคนิคเดียวกับข้อเมื่อสักครู่ โดยการแปลง Column Order date ให้เป็นรูปแบบวันที่ก่อน
pd.to_datetime(df[“Order Date”]).dt.year == 2017
จากนั้นเราต้องการหาผลลัพธ์ของ Column Sales เราก็เลือกเฉพาะ Column นี้มา แล้วใช้ library numpy ในการใช้ function คำนวณยอดขาย และ Print ข้อมูลออกมาแสดง
np.sum()
- ใช้เพื่อคำนวณ ยอดขายรวม
np.average()
- ใช้เพื่อคำนวณ ยอดขายเฉลี่ย
np.std()
- ใช้เพื่อคำนวณ ส่วนเบี่ยงเบนมาตรฐาน ของยอดขาย
TODO 06 – which Segment has the highest profit in 2018

คำถามนี้ไม่ยุ่งยาก User ต้องการให้ดูว่าผลกำไรของปี 2018 เราได้ผลกำไรจากสินค้าในกลุ่ม Segment อะไรมากที่สุด
ผมจึงเลือกที่จะใช้ Groupby ในการจัดหมวดหมู่ของสินค้าแยกตาม Segment และให้แสดงผล Profit หรือกำไรออกมาในทั้งหมดทุกกลุ่มที่มีการขายสินค้าในปีนั้น
TODO 07 – which top 5 States have the least total sales between 15 April 2019 – 31 December 2019
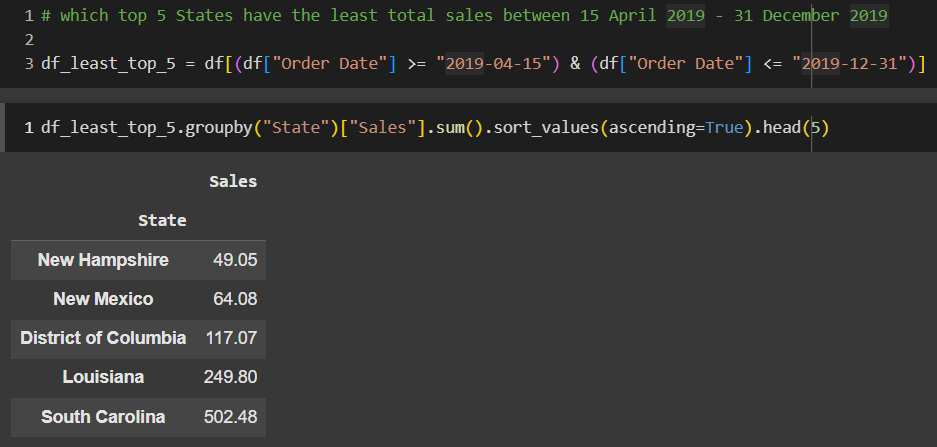
คำถามข้อนี้เราจะไม่ได้ทำการแปลงค่าเป็น datetime แบบข้อก่อนๆ และเนื่องจากเหตุผลนี้ ทำให้ตอนที่ผลเขียนคำสั่ง Filter ข้อมูล column Order Date จึงใส่ ทำการใส่เครื่องหมาย “” ลงไปเพื่อให้สามารถเปรียบเทียบข้อมูลได้อย่างถูกต้อง
จากนั้นเมื่อได้ข้อมูลเปรียบเทียบมาแล้ว ผมได้ทำการ Group by รวมข้อมูลออกมาโดยแบ่งตาม State และเอาข้อมูลยอดขายน้อยที่สุดออกมา โดยใช้คำสั่งดังนี้
df_least_top_5.groupby(“State”)[“Sales”].sum().sort_values(ascending=True).head(5)
ผมทำการเรียงลำดับค่า (Sort) ยอดขาย [“Sales”] จากน้อยสุดไปมากสุด โดยเอาเฉพาะ 5 ค่าแรกมาแสดง .head(5)
TODO 08 – what is the proportion of total sales (%) in West + Central in 2019 e.g. 25%
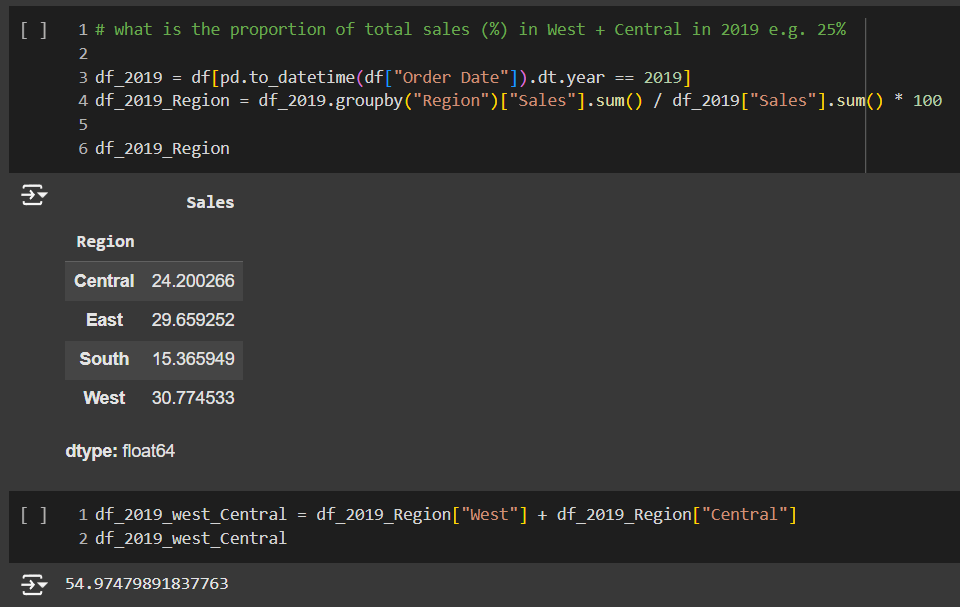
คำถามข้อนี้ ต้องการให้คิด % ยอดขายสินค้าแยกตาม Region ในปี 2019 เราเริ่มจากการ Filter ค่าวันที่เหมือนข้อก่อนๆ
pd.to_datetime(df[“Order Date”]).dt.year == 2019
จากนั้นก็ทำการ Group by แยกตาม Region และให้แสดงค่า column Sales ออกมา
df_2019.groupby(“Region”)[“Sales”].sum()
พอได้ผลลัพธ์เรียบร้อย คำถามคือให้คิดเป็น % ดังนั้นผมจึงนำผลลัพธ์ที่ได้ เอามาหารด้วยค่ายอดค่ารวมทั้งปี 2019 แล้ว คูณด้วย 100 จะได้เป็นค่า % ยอดขายแต่ละภูมิภาค (Region) แล้วนำผลลัพธ์ไปสร้างเป็น Data frame ก้อนใหม่ ใช้ชื่อว่า df_2019_Region
df_2019_Region = df_2019.groupby(“Region”)[“Sales”].sum() / df_2019[“Sales”].sum() * 100
จากนั้นขั้นตอนสุดท้าย คำถามถามว่า สัดส่วนยอดขายรวม (%) ของภาคตะวันตก West รวมกับ ภาคกลาง Central คิดเป็นเท่าไหร่ในปี 2019 ผมจึงใช้วิธีพื้นฐานคือเอาค่าทั้ง 2 Region มาบวกกัน จะได้เท่ากับ 55%
df_2019_west_Central = df_2019_Region[“West”] + df_2019_Region[“Central”]
TODO 09 – find top 10 popular products in terms of number of orders vs. total sales during 2019-2020
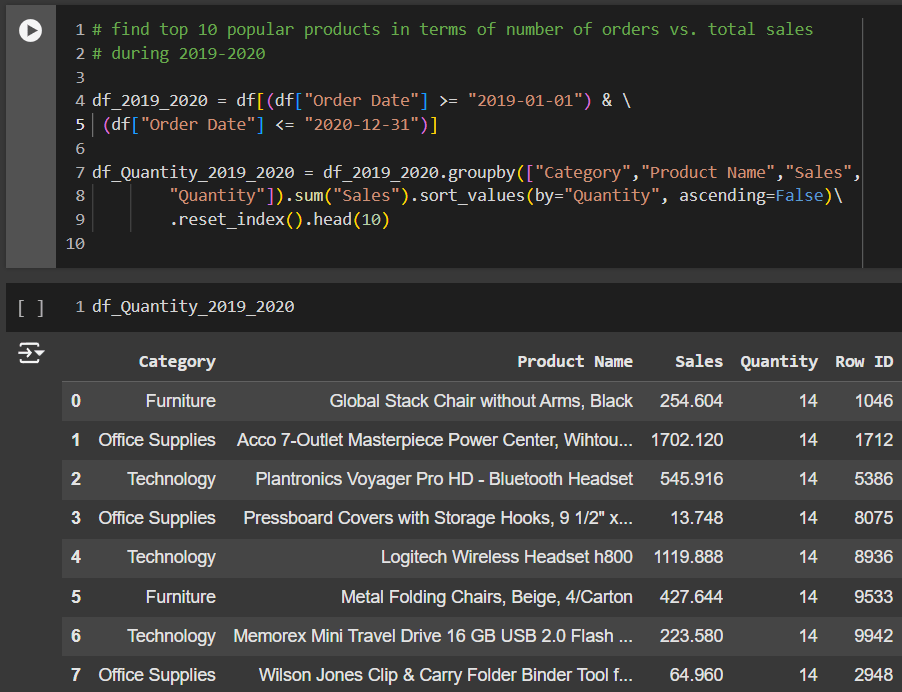
คำถามข้อนี้ต้องการให้หาว่า ช่วงระหว่างปี 2019 – 2020 สินค้าที่ขายดีในแง่ของคำสั่งซื้อ เทียบกับยอดขายรวมมีอะไรน่าสนใจบ้าง 10 ลำดับแรก
ในคำถามนี้ สิ่งที่เราอยากได้คือค่า Quantity หรือจำนวนคำสั่งซื้อ Filter ในปี 2019 – 2020 เพราะฉะนั้นเราเริ่มจากการ Filter ในส่วนนี้ก่อน พร้อมแทนค่าเป็น Data frame ก้อนใหม่ที่ชื่อว่า df_2019_2020
df_2019_2020 = df[(df[“Order Date”] >= “2019-01-01”) & (df[“Order Date”] <= “2020-12-31”)]
จากนั้นเราก็จะทำการ Group by ผลลัพธ์นี้โดย แยกตามประเภทสินค้า Category , ชื่อสินค้า Product name , ยอดขาย Sales , จำนวนคำสั่งซื้อ Quantity
df_2019_2020.groupby([“Category”,”Product Name”,”Sales”, “Quantity”])
จากนั้นก็ SUM ผลรวมยอดขาย และทำการเรียงลำดับ จำนวนคำสั่งซื้อจากมากไปน้อย
.sum(“Sales”).sort_values(by=”Quantity”, ascending=False).reset_index().head(10)
และสุดท้ายแสดงค่าผลลัพธ์ 10 ลำดับแรก
TODO 10 – plot at least 2 plots, any plot you think interesting 🙂
คำถามสุดท้าย ผมได้ทำการนำ dataframe จากข้อก้อนๆมาหาความสัมพันธ์ในรูปแบบกราฟแสดงผลลัพธ์ โดยสร้างออกมา 2 กราฟ ดังนี้

ความสัมพันธ์นี้ แสดงถึงผลกำไรของสินค้า เทียบกับส่วนลด จะเห็นได้ว่าสินค้าที่มีผลกำไรเยอะ ส่วนใหญ่จะเป็นสินค้าที่ไม่มีส่วนลด หรือลดไม่เยอะมาก ไม่เกิน 20% ในทางตรงกันข้ามสินค้าที่มีส่วนลดเยอะ จะไม่สร้างผลกำไรให้กับบริษัท 80%
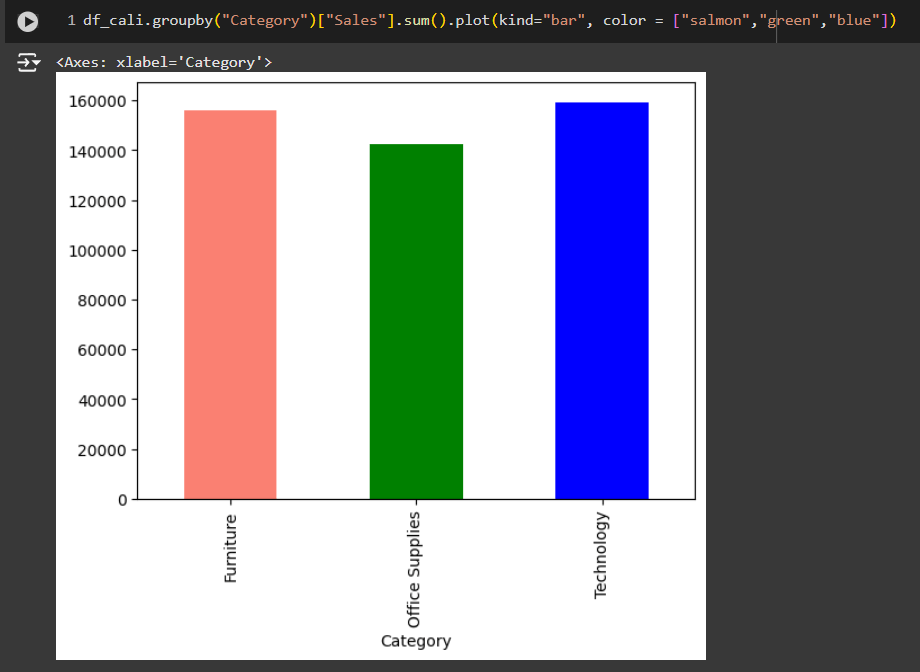
ส่วนกราฟที่ 2 นี้แสดงถึงค่ายอดขายรวมของ State California ที่เราส่งให้เพื่อนไปในตอนต้น โดยการเทียบเป็น Bar Chart ให้ดูว่า สินค้าหมวดหมู่ใดมียอดขายเป็นเท่าไหร่กลุ่มสินค้าตัวไหนยอดขายสูงหรือกลุ่มไหนยอดไหนต่ำ
ก็จบไปเป็นที่เรียบร้อย ต้องบอกว่า Project ตัวอย่างนี้ เป็นการใช้ทักษะที่ได้เรียนจาก Data Science Bootcamp ใน Part ของ Python เพื่อนำมาใช้ตอบคำถามที่ทางอาจารย์ตั้งโจทย์ไว้ หวังว่าทุกท่านจะได้เห็นแนวคิด แล้วก็วิธีการวิเคราะห์ข้อมูล และการจัดการข้อมูลในแนวทางของผมไปกันเรียบร้อยแล้ว หลังจากนี้จะเป็น Project ที่ทำนอกเหนือจากเนื้อหาที่เรียน โดยการหยิบ dataset จาก kaggle มาวิเคราะห์และตอบคำถาม จากโจทย์ที่ผู้เชี่ยวชาญด้านวิเคราะห์ข้อมูลหรือในที่นี้คือ Gemini เป็นผู้คิดโจทย์ให้
หวังว่าจะมีประโยชน์กับทุกท่านไม่มากก็น้อยนะครับ
Project อื่นๆ ที่อยู่บน Google Colab ดูเพิ่มเติมได้จาก Link ด้านล่างนี้ 🙂

Finally, welcome to
THIS IS MY PROJECT
PROJECT#2 GLOBAL YOUTUBE CHANNEL
